Download Classification Without Machine Learning Background
by
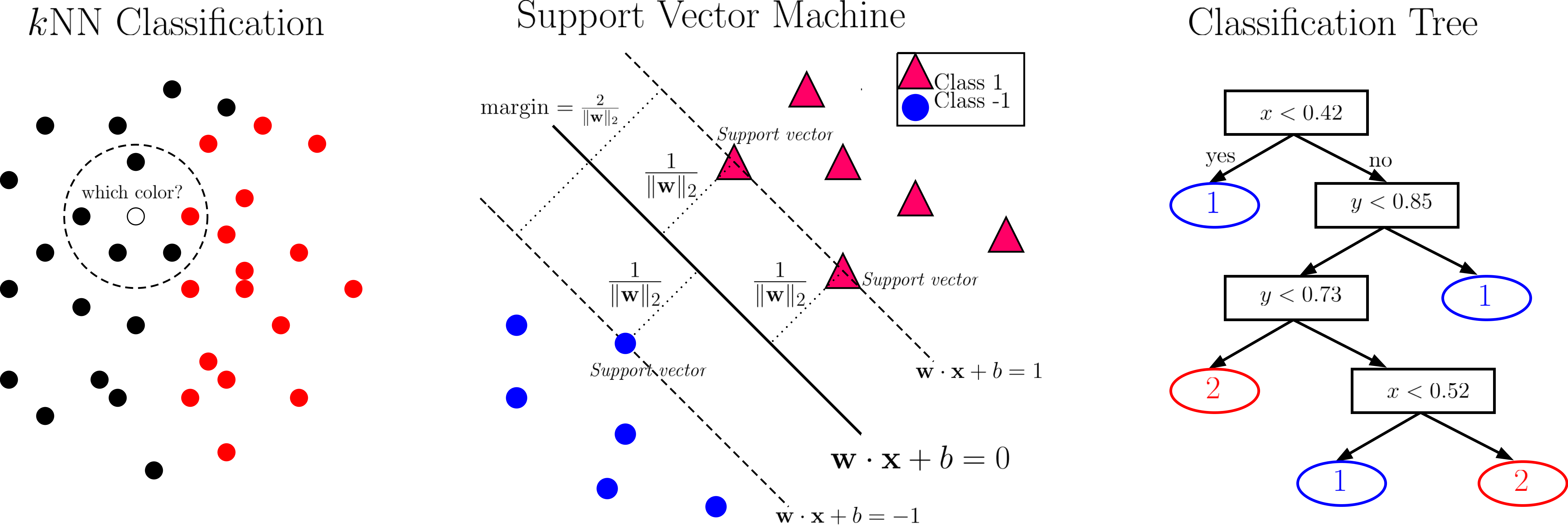
Download Classification Without Machine Learning Background. As we descend down the tree, each node adds a condition, subsetting our training data into smaller and smaller subgroups: So our training subsets shrink pretty quickly and eventually lack statistically valid sample sizes.
Course webpage for Math 251 Statistical and Machine … from www.sjsu.edu
This is modelled by neural networks. The project was abandoned because the projected effort of maintaining the rules was too great. Prune the rule (reduced error metric) 4.
Python users can also try wittgenstein.
Let's see how everything comes together. See full list on towardsdatascience.com So our training subsets shrink pretty quickly and eventually lack statistically valid sample sizes. On behalf of data science, let me say, “it’s not you, it’s me.” if you’re the kind of person who likes to keep a tidy mind, here’s why your lip might curl in disgust when confronted with the title question: